
Проблема «галлюцинаций» в LLM — это не баг, который можно исправить промптом. Это фундаментальное ограничение архитектуры Transformer. Согласно исследованию Stanford University «HaluEval», даже топовые модели могут генерировать до 20–30% недостоверного контента в отсутствие внешнего контекста.
Для бизнеса в 2026 году цена такой ошибки — судебные иски и потеря репутации. Решение лежит в плоскости Retrieval-Augmented Generation (RAG).
1. Почему стандартные методы внедрения AI провалились?
Многие компании наступили на одни и те же грабли, пытаясь «прикрутить» ИИ к бизнесу простыми способами. Основная ошибка заключалась в попытке заставить нейросеть зазубрить данные компании, вместо того чтобы научить её ими пользоваться.
Проблема №1: Эффект «в одно ухо вылетело» (Lost in the Middle)
Когда появились нейросети, способные «проглотить» за раз тысячи страниц текста, бизнес решил: «Просто загрузим в чат все наши инструкции, и он во всем разберется». Но на практике сработал феномен, подтвержденный учеными из Stanford: нейросеть отлично помнит начало документа и его конец, но практически полностью «забывает» то, что написано в середине. Если важное условие вашей страховки или скидки находится на 50-й странице файла, ИИ его проигнорирует и начнет уверенно фантазировать.
Проблема №2: Каша в голове (Галлюцинации смешивания)
У каждой нейросети есть «багаж знаний», на котором её учили (весь интернет). Когда вы пытаетесь добавить туда свои данные через дообучение (Fine-tuning), происходит конфликт. ИИ начинает путать ваши внутренние цены с ценами конкурентов из интернета или накладывает законы 2021 года на ваши правила 2026-го. На выходе получается убедительный, но абсолютно ложный ответ.
Проблема №3: Золотые запросы (Экономический тупик)
Использовать ИИ без специальной настройки — это финансово больно. Нейросеть устроена так, что при каждом вашем вопросе она заново «перечитывает» всё, что вы в неё загрузили.
- Хотите узнать адрес офиса? ИИ перечитает 100 страниц регламентов.
- Хотите уточнить данные по договору? ИИ снова перечитает те же 100 страниц. В итоге один простой ответ может стоить вам $1–2. В масштабах компании это превращается в миллионные счета за воздух.
Цитата: «Использовать дообучение или длинные промпты для работы с документами в 2026 году — это всё равно что заставлять сотрудника заново перечитывать всю библиотеку компании каждый раз, когда ему нужно просто ответить на телефонный звонок».
Вывод: Нейросеть — это мощный процессор, но плохой архив. Чтобы она работала точно, ей нужна внешняя память. И эта технология называется RAG.
2. Архитектура RAG: Как это работает на самом деле?
RAG (Retrieval-Augmented Generation) — это технология «дополненной генерации». Вместо того чтобы полагаться только на свои встроенные знания (полученные при обучении), нейросеть использует вашу базу данных как внешнюю память.
Механика процесса выглядит так:
- Запрос: Пользователь задает вопрос (например: «Какая скидка у клиента 'X' по договору?»).
- Поиск (Retrieval): Система мгновенно находит нужный абзац в ваших внутренних файлах или CRM.
- Генерация (Generation): ИИ читает этот кусок текста и на его основе пишет точный ответ.
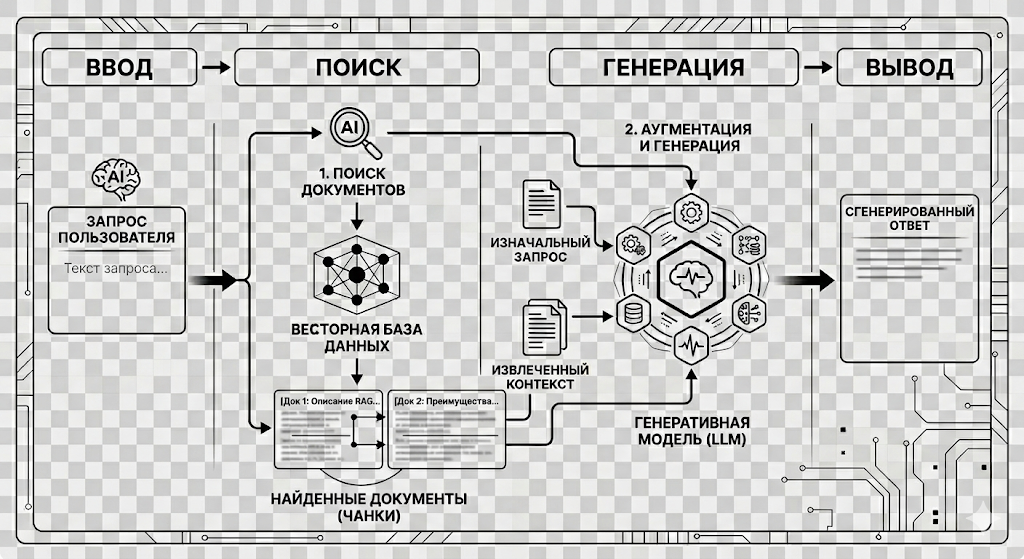
Цитата: Как отмечает IBM в своих исследованиях ИИ для бизнеса: «Главное преимущество RAG заключается в том, что он превращает генеративный ИИ из творческого рассказчика в надежного корпоративного аналитика, который оперирует фактами, а не вероятностями».
Технологический стек 2026: Почему RAG в 100 раз дешевле обычных запросов
1. Semantic Chunking (Смысловая нарезка)
Мы отказались от механической резки текста по количеству знаков. Система использует ИИ, чтобы разделить ваши данные на логические блоки (абзацы, статьи, разделы), сохраняя контекст каждой мысли.
- Бизнес-эффект: ИИ больше не нужно «проглатывать» 100 страниц документа, чтобы найти один пункт договора. Система подает на вход нейросети только конкретный 2-страничный фрагмент, где содержится ответ. Это в 100 раз снижает затраты на токены и исключает риск того, что ИИ «запутается» в лишней информации.
2. Vector Databases (Векторные базы данных)
В 2026 году лидеры (Pinecone, Milvus, Weaviate) используют алгоритмы HNSW для мгновенного поиска. Ваши данные превращаются в цифровые отпечатки смыслов.
- Бизнес-эффект: Это поиск не по словам, а по значению. Если клиент спрашивает «Как вернуть товар?», система мгновенно вытаскивает фрагменты про «аннулирование сделки» и «права потребителя», даже если в вопросе не было этих слов. Поиск по базе из миллиона документов занимает доли секунды.
3. Re-ranking (Финальный фильтр)
После того как база нашла подходящие фрагменты, модель Cross-Encoder проводит их экспертную оценку на соответствие запросу.
- Бизнес-эффект: Это «контрольный выстрел» по галлюцинациям. Если база данных выдала 5 похожих инструкций, Re-ranking выберет из них одну самую актуальную (например, последнюю версию регламента). Нейросеть-генератор получает только идеальный материал для ответа, что гарантирует 99% точности.
Итог для ROI
Благодаря этой цепочке, вы платите только за обработку 0,1% от всего объема ваших данных — именно тех строк, которые реально нужны для ответа. Это снижает себестоимость одного запроса до $0.00003, делая систему дешевле и быстрее любого штатного сотрудника.
3. Решение проблемы галлюцинаций через Grounding: Как заставить ИИ отвечать только по фактам
Если предыдущие этапы (Chunking и Vector DB) отвечали за то, как найти информацию, то Grounding (заземление) отвечает за то, чтобы ИИ не врал, когда пишет ответ.
Цитата: Grounding (заземление) в нейросетях — это процесс установления связи между абстрактными символами (словами, понятиями), которыми оперирует модель, и конкретными, достоверными данными или реальным физическим миром.
В 2026 году это единственный способ гарантировать юридическую и финансовую безопасность корпоративного чат-бота.
Золотым стандартом является Self-RAG и Corrective RAG (CRAG).
- Self-RAG( Встроенный «детектор лжи»):
- В обычных системах ИИ обязан выдать ответ, даже если данные в базе сомнительные. В продвинутой архитектуре (Self-RAG) модель сначала оценивает качество найденных кусков текста, а далее либо выдает корректный ответ, либо «Я не нашел надежного ответа», вместо того чтобы выдумывать.
- Attribution (проверка источника в 1 клик):
Главная проблема ChatGPT в том, что вы не знаете, откуда он взял ответ. В системе RAG с Attribution каждое предложение ИИ подтверждает ссылкой на ваш документ. Простыми словами: Рядом с ответом «Ваша скидка 15%» будет стоять активная ссылка: [Договор_№124, стр. 3]. Менеджер или клиент может кликнуть и сразу увидеть оригинал документа. ИИ превращается из «болтуна» в удобный интерфейс к вашему архиву. Вы всегда можете проверить, на чем основан ответ.
«RAG — это не просто надстройка, это способ заземлить (grounding) абстрактные рассуждения нейросети на твердые факты вашего предприятия», — из технического отчета NVIDIA «Generative AI for Enterprises».
По данным аналитики, внедрение RAG в 2025-2026 гг. дает следующие результаты:
- -40% времени на поиск информации сотрудниками.
- 95% точность ответов (Ground Truth).
Снижение стоимости обработки запроса до $0.00003 (0.003 цента) при правильной оптимизации базы.
4. Экономика внедрения: Анализ ROI и стоимости владения (TCO)
Заключение
Внедрение ИИ сегодня — это не вопрос моды, а вопрос выживания. Технология RAG делает искусственный интеллект безопасным, точным и, что немаловажно, дешевым инструментом.
Хотите внедрить RAG с минимальной стоимостью запроса? Оставьте заявку на нашем сайте, и мы проведем аудит ваших данных для автоматизации.
FAQ
Для базовой настройки существуют low-code платформы, но для достижения стоимости в 0.003 цента за запрос потребуется профессиональный архитектор ИИ-решений для настройки семантического поиска.
Да, технология позволяет развернуть локальные языковые модели, что исключает передачу данных сторонним сервисам.

